Spectrogram Inversion: Cheap, Good and Real-Time!
If you work with real-time audio and/or with spectrograms, you may be interested in our latest publication at InterSpeech 2025, resulting from my 2024 internship at Meta Reality Labs in Cambridge (UK):
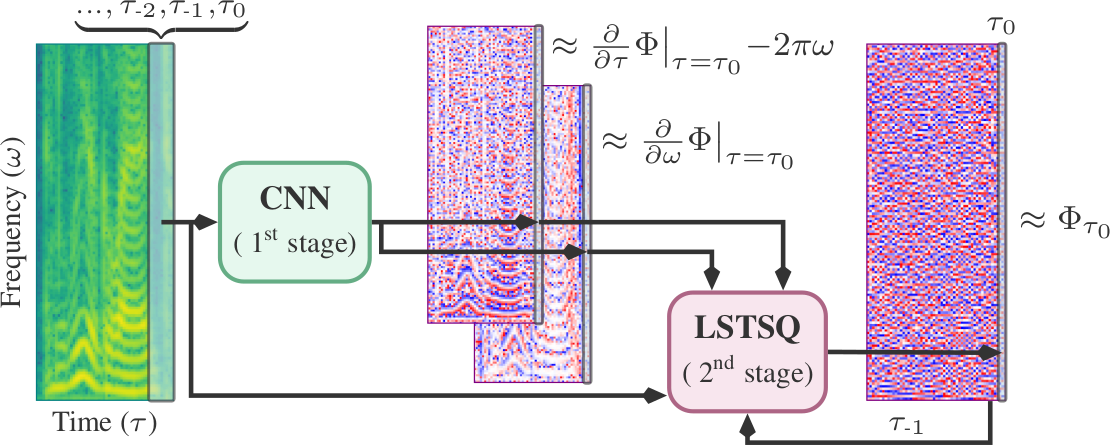
Imagine you want to perform a low-latency audio generative task such as speech enhancement or live translation, on a tiny computer:

To limit computation, many “cheap” pipelines benefit from working directly with spectrograms. The problem is that, while spectrograms are very nice to work with, phases are not! Luckily, the Gradient Theorem articulates a really neat connection between spectrograms and their phases:
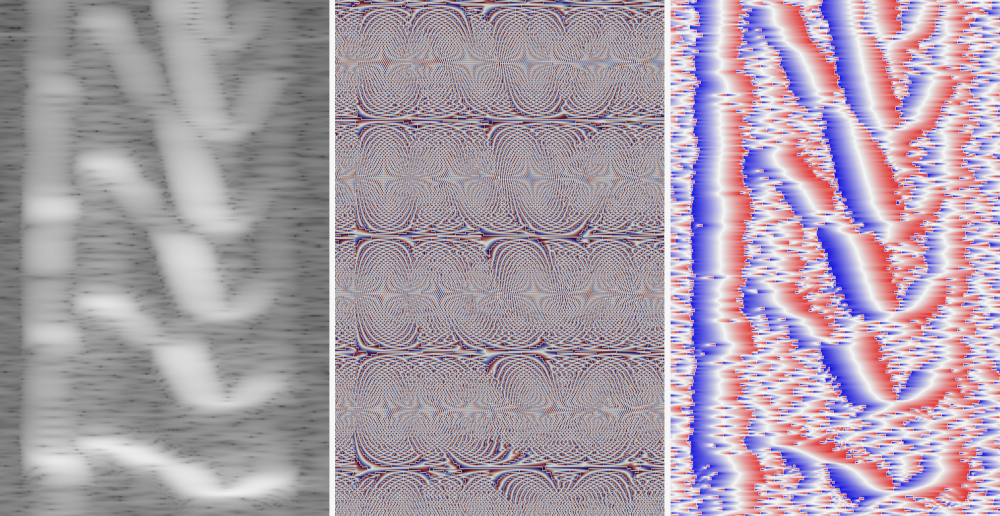
This allows us to directly obtain information of the phases from the magnitudes! And as it turns out, it leads to very high-quality and low-latency results when combined with deep learning.
In our work, we managed to make the whole pipeline much faster and smaller without compromising any of the good quality, by proposing a tiny, causal CNN and leveraging a neat numerical trick to solve a least-squares system in linear time and memory (bringing it down from cubic).
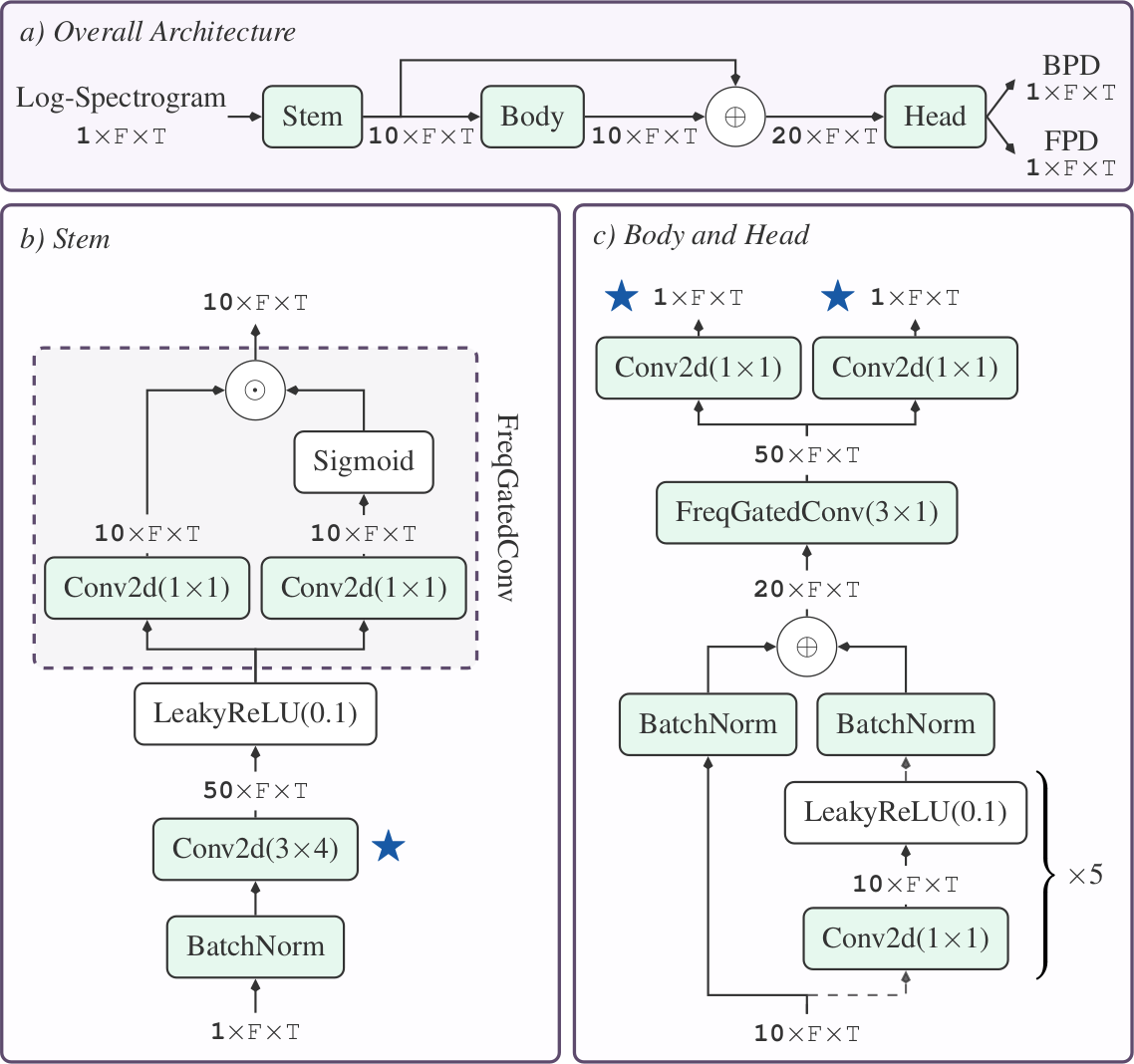
The result: Efficient, real-time and high-quality speech spectrogram inversion! Check out our paper and presentation linked below for more details, and of course, a big shout-out 🗣 to my collaborators and supervisors from Meta!
- Paper: [arXiv], [pdf]
- Audio samples: https://andres-fr.github.io/efficientspecinv
- Presentation: [pdf]
@inproceedings{fernandez25_interspeech,
title = {{Efficient Neural and Numerical Methods for High-Quality Online Speech Spectrogram Inversion via Gradient Theorem}},
author = {Fernandez, Andres and Azcarreta Ortiz, Juan and Bilen, Çağdaş and Monge Alvarez, Jesus},
year = {2025},
booktitle = {{Interspeech 2025}},
pages = {3449--3453},
doi = {10.21437/Interspeech.2025-439},
issn = {2958-1796},
}